
In Meaningful work interviews I talk to people about their area of work and expertise to better understand what they do and why it matters to them.
Matej Martinc is a Ph.D. researcher at “Jožef Stefan” Institute in the Department of Knowledge Technologies where he invents new approaches on how to work and analyze written text. He explained to me the basics of Natural Language Processing (NLP), why neural networks are amazing, and how one gets started with all of this. In the second half, he shared how he ended up in Computer Science with a Philosophy degree and why working for companies like Google is not something that interests him.
How do people introduce you?
They introduce me as a researcher at the IJS institute. I’m in the last year of my Ph.D. thesis research. I’m mostly working on Natural Language Processing (NLP). NLP is a big field and I’m currently exploring several different areas.
I initially started by automatically profiling text authors by their style of writing – we can detect their age, gender, and psychological properties. I also worked on automatic identification of text readability. We’ve also created a system to detect Alzheimer’s patients based on their writing.
Lately, I’ve been working on automatic keyword extraction and detecting political bias in word usage in media articles. I’m also contributing to research on semantic change – how word usage changes through time.
References to research that Matej is referencing throughout this interview. I encourage you to read them as they’re written in a very clear language.
Scalable and Interpretable Semantic Change Detection
[..] We propose a novel scalable method for word usage change detection that offers large gains in processing time and significant memory savings while offering the same interpretability and better performance than unscalable methods. We demonstrate the applicability of the proposed method by analyzing a large corpus of news articles about COVID-19
Zero-Shot Learning for Cross-Lingual News Sentiment Classification
In this paper, we address the task of zero-shot cross-lingual news sentiment classification. Given the annotated dataset of positive, neutral, and negative news in Slovene, the aim is to develop a news classification system that assigns the sentiment category not only to Slovene news, but to news in another language without any training data required. [..]
Automatic sentiment and viewpoint analysis of Slovenian news corpus on the topic of LGBTIQ+
We conduct automatic sentiment and viewpoint analysis of the newly created Slovenian news corpus containing articles related to the topic of LGBTIQ+ by employing the state-of the-art news sentiment classifier and a system for semantic change detection. The focus is on the differences in reporting between quality news media with long tradition and news media with financial and political connections to SDS, a Slovene right-wing political party. The results suggest that political affiliation of the media can affect the sentiment distribution of articles and the framing of specific LGBTIQ+ specific topics, such as same-sex marriage.
Can you start by explaining some background about NLP (Natural Language Processing) to start with?
As a first step, it’s good to consider how SVM (support vector machine) classifiers and decision tree techniques used for classification work. Very broadly speaking, they operate on a set of manually crafted features extracted from the dataset that you train your model on. Examples of that type of features would be: “number of words in a document” or a “bag of words model” where you put all the words into “a bag” and a classifier learns which words from this bag appear in different documents. If you have a dataset of documents, for which you know into which class they belong to (e.g., a class can be a gender of the author that wrote a specific document), you can train your model on this dataset and then use this model to classify new documents based on how similar these documents are to the ones in the dataset on which the model was trained. The limitation of this approach is that these statistical features do not really take semantic relation between words into account, since they are based on simple frequency-based statistics.
About 10 years ago a different approach was invented using neural networks. What neural networks allow you to do is to work with unstructured datasets because you don’t need to define these features (i.e., classification rules) in advance. You train them by inputing sequences of words and the network learns on itself how often a given word appears closer to another word in a sequence. The information on each word is gathered in a special layer of this neural network, called an embedding layer that is basically a vector representation that encodes how a specific word relates to other words.
What’s interesting is that synonyms have a very similar vector representation. This allows you to extract relations between words.
An example of that would be trying to answer: “Paris in relation to France” is the same as “Berlin in relation to (what?)”. To solve this question you can take the embedding of Paris, subtract the embedding of France and add embedding of Berlin and you’ll get an embedding as an answer – Germany. This was a big revolution in the field as it allows us to operationalize relations in the context of languages. The second revolution came when they invented transfer learning, a procedure employed for example in the BERT neural network that was trained on BookCorpus with 800 million words and English Wikipedia with 2500 million words.
In this procedure, the first thing you want to do is to train a language model. You want the model to predict the next word in a given sequence of words. You can also mask words in a given text and train the neural network to fill the gaps with the correct words. What implicitly happens in such training is that the neural network will learn about semantic relations between words. So if you’re doing this on a large corpus of texts (like billions of words in BERT) you get a model that you can use on a wide variety of general tasks. Because nobody had to label the data to do the training it means that it’s an unsupervised model.
Are you working with special pre-trained datasets?
I’m now mostly working with unsupervised methods similar to the BERT model. So what we do is to take that kind of model and do additional fine-tuning on a smaller training set that makes it better suited for that specific research. This approach allowed us to do all of the research that I’m referencing here.
A different research area that doesn’t require additional training is to employ clustering on the embeddings of these neural networks. You can take a corpus of text from the 1960s and another one from the 2000s. We can then compare how usage of specific embeddings (words) compare between these two collections of texts. That’s essentially how we can study how the semantic meaning of words changed in our culture.
Modern neural networks can also produce embedding for each usage of a word, meaning that words with more than one meaning have more than one embedding. This allows you to differentiate between Apple (software company) and apple (fruit). We used this approach when studying how different words connected to COVID changed through time. We generated embeddings for each word appearance in the corpus of news about COVID and clustered these word occurrences into distinct word usages. Two interesting terms that we identified were diamond and strain. For strain, you can see the shift from using it in epidemiological terms (strain virus) to a more economic usage in later months (financial strain).
What we showed with our research is that you can detect changes even across short (monthly) time periods. There’s a limit to how accurately we can identify the difference. It’s often hard even for humans to decide how to label such data. We can usually get close to humane performance by using our unsupervised methods.
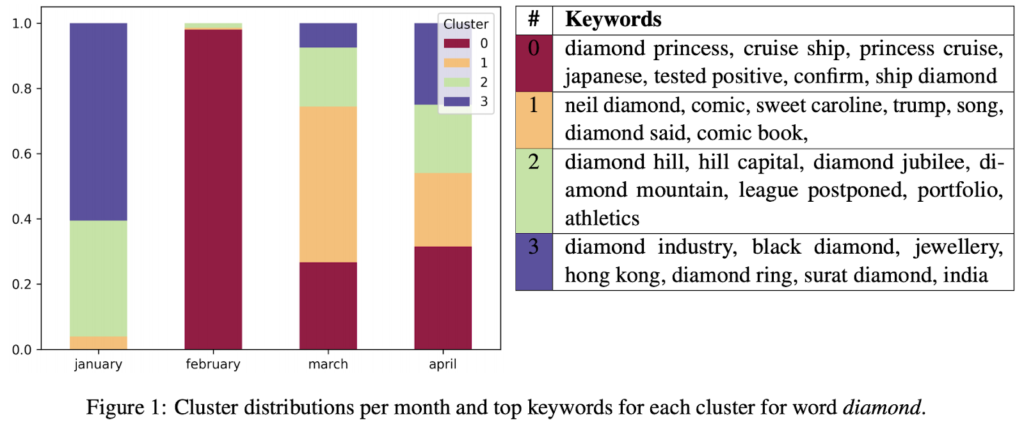
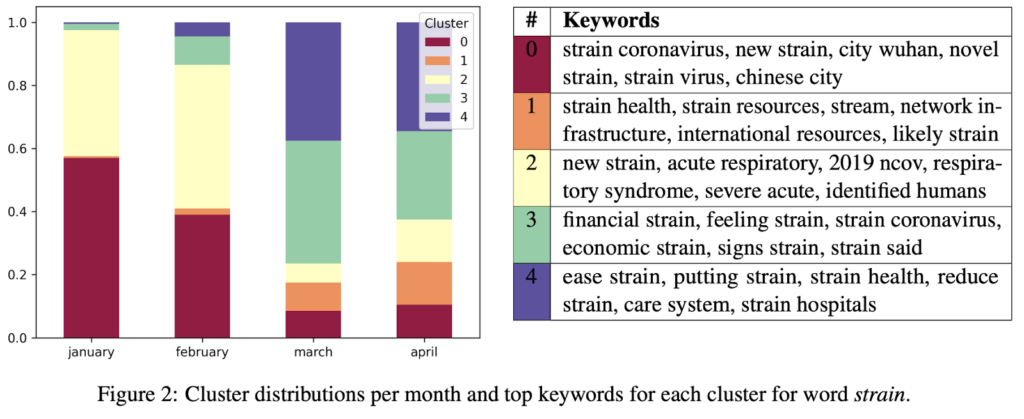
Does this work for Non-English languages?
You can use the same technology with a non-English language and we’re successfully using it with Slovenian language. In the case of viewpoint analysis of Slovenian news reporting, we’ve discovered a difference in how the word deep is used in different context. Mostly because of the deep state that became a popular topic in certain publications.
For our LGBTIQ+ research, we can show that certain media avoids using the word marriage in the context of LGBTIQ+ reporting and replaces it with terms like domestic partnership. They’re also not discussing LGBTIQ+ relationship within the context of terms such as family. We can detect the political leaning of the media based on how they write about these topics.
We just started with this research on the Slovenian language so we expect that we’ll have much more to show later in the year.
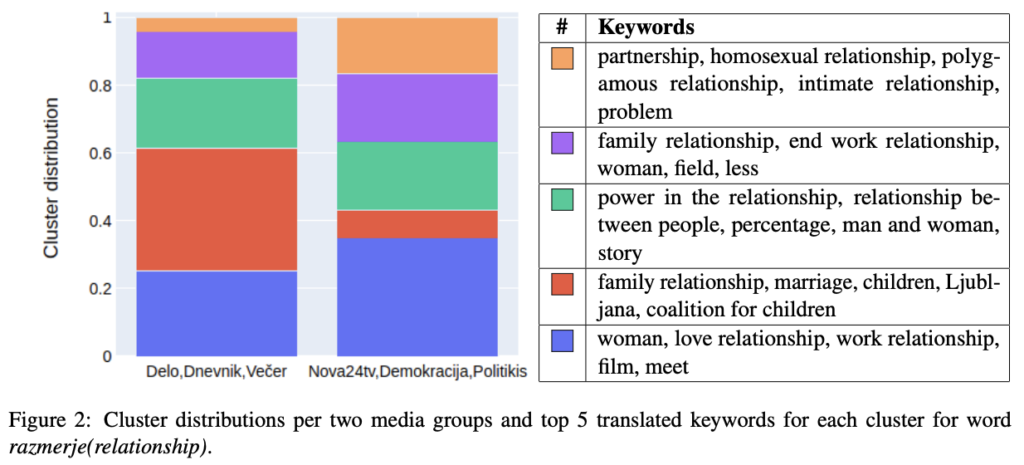
So far you’ve talked about analysis and understanding of texts. What other research are you doing?
We’re working on models for generating texts as part of the Embeddia project. The output of this research also works with the Slovenian language.
We’re also investigating if we can transfer embeddings between languages. We have a special version of the BERT neural network that has been trained on 100+ different language Wikipedias. What we’ve found out is that you can take a corpus of texts in the English language, train the model on it to, for example, detect the gender of the author, and then use that same model to predict the gender of the author of some Slovenian text. This approach is called a zero-shot transfer.
How approachable is all this research and knowledge? Do I need a Ph.D. to be able to understand and use your research?
It takes students of our graduate school about a year to become productive in this field. The biggest initial hurdle is that you need to learn how to work with neural networks.
Good thing is that we now have very approachable libraries in this field. I’m a big fan of PyTorch as it’s well integrated with the Python ecosystem. There’s also TensorFlow that’s more popular in the industry and less in research. I found it harder to use for the type of work we’re doing and harder to debug. With PyTorch it takes about a month or two for our students to understand the basics.
In our context, it’s not just about using the existing neural networks and methods. Understanding the science part of our field and how to contribute via independent paper writing and publishing it’s usually about 2 years.
How easy is it to use your research in ‘real-world’ applications?
We have some international media companies that are using our research in the area of automatic keyword extraction from text. We’re helping them with additional tweaking of our models.
Overall we try to publish everything that we do under open access licenses with code and datasets publicly available.
What we don’t do is maintain our work in terms of production code. It’s beyond the scope of research and we don’t have funding to do it. It’s also very time-consuming and it doesn’t help us with our future research. That’s also what I like about scientific research. We get to invent things and we don’t need to maintain and integrate them. We can shift our focus to the next research question.
So in practice, all of our research is available to you but you’ll need to do the engineering work to integrate it with your product.
Let’s shift a bit to your story and how you got into this research. How did you get here?
I first graduated in philosophy and sociology in 2011, at the time when Slovenia was still recovering from the financial crisis. While I considered Ph.D. in philosophy I decided that there are not many jobs for philosophers. That’s why I’ve enrolled in a Computer Science degree that offered better job prospects.
During my Computer Science studies, I was also working in different IT startups. I quickly realized that you don’t have a lot of freedom in such an environment. Software engineering was too constrained for me in terms of what kind of work I could do.
After I graduated I took the opportunity to do Erasmus Exchange and I went to University in Spain. In that academic environment, I found the opposite approach. I received a dataset, a very loose description of a problem, and complete freedom to decide on how I’m going to approach and solve the problem.
When I returned to Slovenia I decided to apply to a few different laboratories inside IJS to see if I could continue with academic research. I’ve got a few offers and accepted the offer from the laboratory where I’m working today.
I also decided to focus on NLP and language technologies as I’m still interested in doing philosophical and sociological research. Currently, I have the freedom to explore these topics in my research field without too many constraints. I’m also really enjoying all the conferences and travel that comes with it. Due to the fast-changing nature of my field, all the cutting-edge research is presented at conferences, and publishing in journals is just too slow. It takes over a year to publish a paper but there’s groundbreaking research almost monthly.
How do you see research done at FAANG (Facebook, Amazon, Apple, Netflix, Google) companies? We know that they’re investing a large amount of money into this field and have large research teams.
They’re doing a lot of good research. At the same time, they’re also often relying more on having access to a large number of hardware resources that we don’t. This can be both a blessing and a curse. At the moment I don’t see their research being that much better from the findings from universities. Universities are also more incentivized to develop new optimization techniques as they can’t use brute hardware force for their research.
Are you considering working for a FAANG company after your Ph.D.?
Not really. I already have a lot of freedom in my research and I can get funding to explore the areas that interest me. If I would work inside a FAANG company I would need to start at the bottom of the hierarchy and also be limited by their research agenda.
I also really like living in Slovenia and I don’t want to relocate to another country. At the same time, I’m excited about potential study/researchexchanges as I enjoy collaborating with researchers at foreign institutions.
What are some good resources to follow in your field?
You can follow the current state of the art at:
- Proceedings from Annual Meeting of the Association for Computational Linguistics, European, and North American editions collected at https://www.aclweb.org/anthology/
- Neural Information Processing Systems (NIPS) conference: https://nips.cc/
Papers describing paradigm shifts in the field of NLP:
- Discovery of embeddings: Efficient Estimation of Word Representations in Vector Space
- A new type of neural networks (transformers) that are now being widely used in NLP: Attention Is All You Need
Unsupervised language model pretraining and transfer learning: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
What I learned from talking with Matej
- Recognizing what kind of work makes you happy allows you to optimize your job or clients so that you do such work.
- Natural Language Processing is a very approachable technology and not something that only big companies can use.
- There are many opportunities to bring research findings into the industry. It does require expertise and connections to both fields.
- These technologies now also work for the Slovenian language.